实验中心
2024年04月17日
目录:
一、写出清晰的指令
二、提供参考文本
三、将复杂的任务拆分为更简单的子任务
四、给模型时间“思考”
五、使用外部工具
六、系统地测试更改
今天来讲讲 OpenAI 官方文档中的 Prompt engineering (提示词工程指南)。
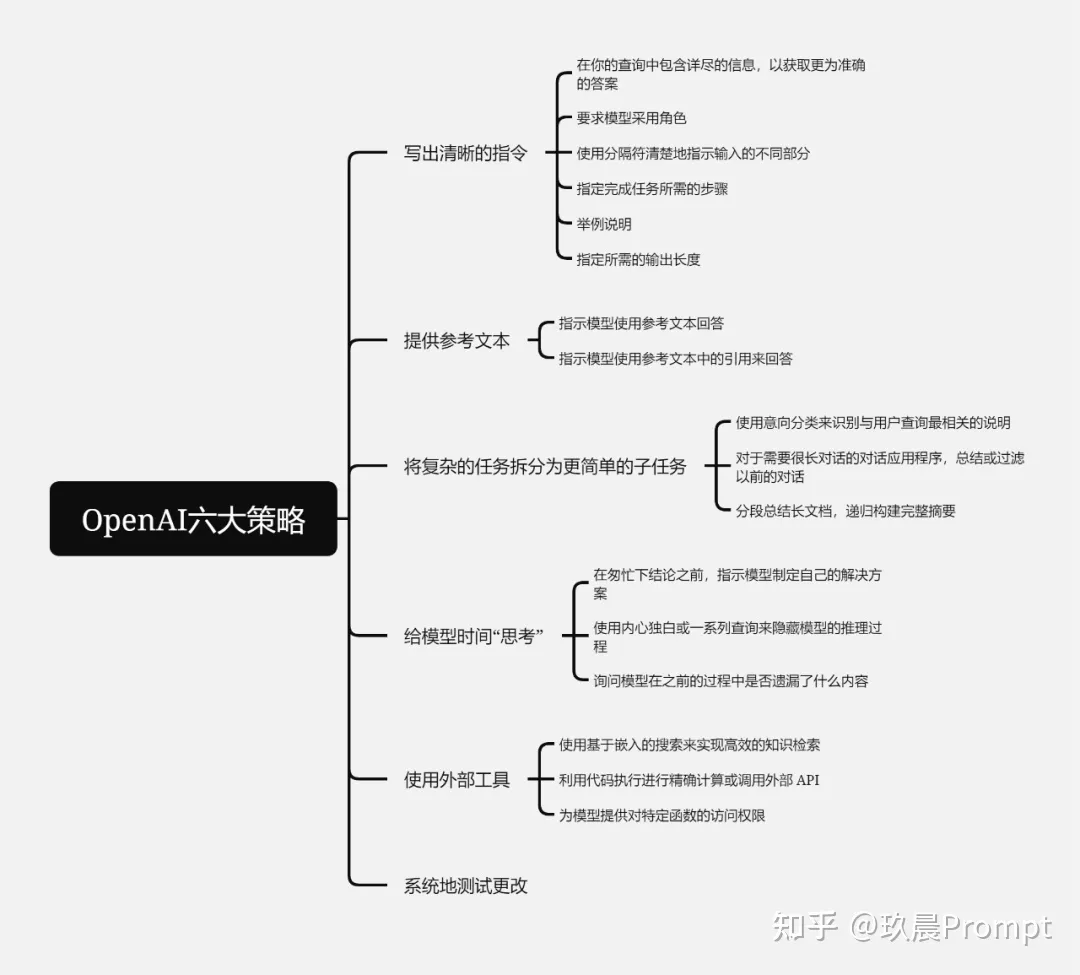
OpenAI 提到六大策略,分别是:
00001. Write clear instructions(写出清晰的指令)
00002. Provide reference text(提供参考文本)
00003. Split complex tasks into simpler subtasks(将复杂的任务拆分为更简单的子任务)
00004. Give the model time to "think"(给模型时间“思考”)
00005. Use external tools(使用外部工具)
00006. Test changes systematically(系统地测试更改)
这就像人与人沟通一样,我们需要把话讲清楚,不然对方怎么会理解我们的需求呢?所以,写出清晰的指令,是对话的核心。那如何写出清晰的指令,OpenAI 官方给出了6条小技巧:
简单来说就是把话说的详细些,尽量多的去提供些细节和上下文,否则就是在让模型猜测我们的意图。
比如:不要说:谁是总统?
而是说:谁是 2021 年的墨西哥总统,选举多久举行一次?
我们可以把大模型当成一个演员,自己当导演,给它某个角色剧本进行表演,这样,它就会更专业。
比如:充当一个幽默的写作助手,当我请求帮助写东西时,你会回复一份文档,每个段落中至少包含一个笑话或俏皮的评论。

使用三引号、XML 标记、章节标题等分隔符可以帮助划分要区别对待的文本部分,可以帮助大模型更好的理解文本内容。
比如:将三引号中的内容翻译成英文。"""输入文本"""

有些任务能拆就拆,最好指定为一系列步骤,然后明确的写出这些步骤可以使模型更容易遵循它们。
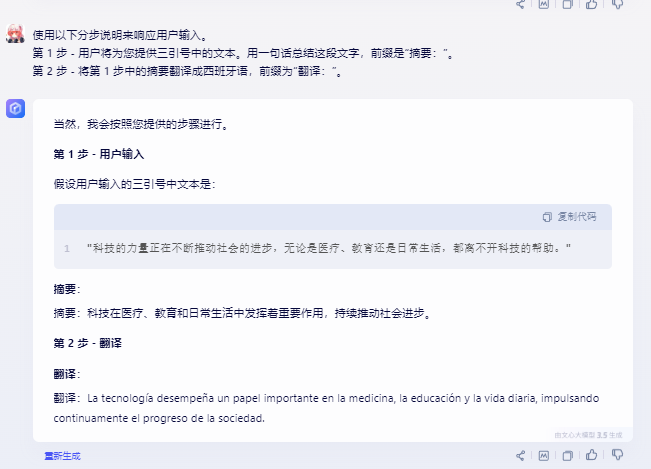
比如:使用以下分步说明来响应用户输入。
第 1 步 - 用户将为您提供三引号中的文本。用一句话总结这段文字,前缀是“摘要:”。
第 2 步 - 将第 1 步中的摘要翻译成西班牙语,前缀为“翻译:”。
先给大模型例子,让大模型按照我给的例子进行输出,这就是所谓的少样本提示。
比如:按三引号内容的风格来写xxx。"""传承国风,砥砺前行,顶流之选,闪耀时代。"""

要求模型按照我们指定的长度输出答案。这个长度可以是单词、句子、段落、项目符号等的数量。但中文的效果不是很准确,通常只是个大概,具体多少个字肯定是不精准的,但多少段这种效果就比较好。
给模型提供与当前提问内容相关的信息,可以指导模型利用这些信息来构建答案,从而降低模型胡说八道的概率。
我们提供信息,让模型使用我们提供的信息来组成其答案。
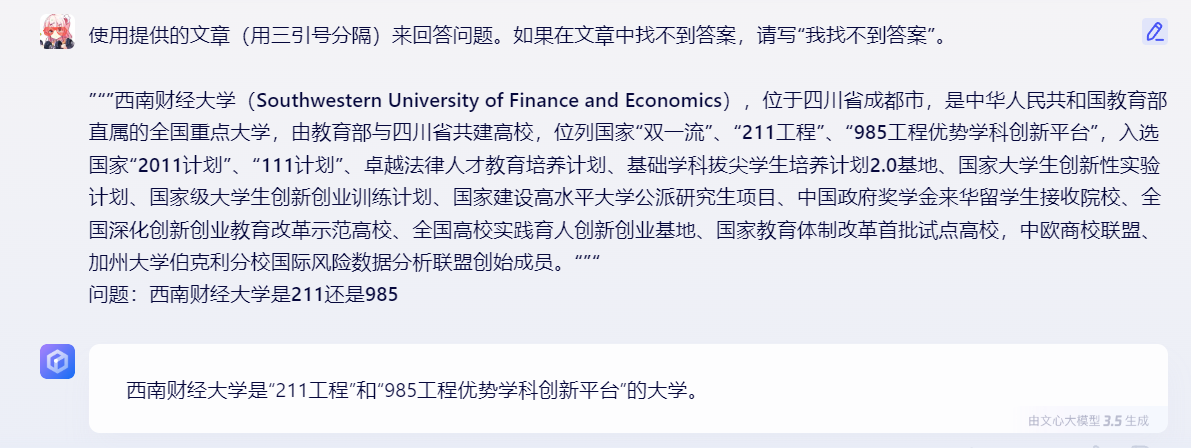
比如:使用提供的文章(用三引号分隔)来回答问题。如果在文章中找不到答案,请写“我找不到答案”。
<插入文章,每篇文章用三引号分隔>
问题:<在此处插入问题>
如果已经提供参考文本,则可以通过引用所提供文档中的段落来请求模型在其答案中添加引文。
比如:您将获得一个由三引号分隔的文档和一个问题。您的任务是仅使用提供的文档来回答问题,并引用用于回答问题的文档的段落。如果文档不包含回答此问题所需的信息,则只需写:“信息不足”。如果提供了问题的答案,则必须用引文进行注释。使用以下格式引用相关段落 ({“citation”:...})。
“”“<在此处插入文档>”“”
问题:<在此处插入问题>
一件复杂的任务交给我们来作,出错的概率也很大,模型也不例外。但如果把复杂的任务拆解一个个简单的子任务,那么出错的概率就会骤然降低。
通过分析用户提问的目的,将这些提问分到不同的类别里。这样做可以帮助系统更准确地理解用户想要什么,并给出更合适的回答。
比如,假设对于客户服务应用程序,查询可以按如下方式进行有用的分类:

根据客户查询的分类,可以向模型提供一组更具体的指令,以便其处理后续步骤。例如,假设客户需要“故障排除”方面的帮助。

模型的上下文长度有限,因此模型只能记住有限的内容。可以用总结或过滤的方法处理以前的对话。这就像是把之前的长篇大论压缩成几句话的要点,或者挑出几个重要的信息点。这样做能帮助保持对话的连贯性,同时避免因为对话太长而超出模型的记忆范围。
模型具有固定的上下文长度,因此不能用于汇总长度超过上下文长度减去单个查询中生成的摘要长度的文本。比如让模型总结一本书,基本都是超 Token 上限了,所以可以使用一系列查询来总结文档的每个部分。章节摘要可以连接和总结,生成摘要的摘要。这个过程可以递归地进行,直到总结整个文档。OpenAI 在之前的研究中已经使用 GPT-3 的变体研究了这种总结书籍的过程的有效性。
让模型有充足的时间来处理和分析数据,尤其是在执行复杂任务时。这不是真正的思考,而是模型在分析输入、寻找解决方案和生成回应的过程。在处理需要深度学习或复杂计算的任务时,确保模型有足够的处理时间可以帮助提升结果的准确性和可靠性。
比如做数学题,我们都知道模型的数学能力很差,一会对一会错的,答案很随机,但是如果你让它先自己做一遍,再去判断对与不对,结果就会准确多了。
这个就像是模型在"心里"默默地思考问题,然后只告诉你最后的答案,而不是把思考的每一步都展示出来。这样做的目的是让交流更简洁,只给你最重要的信息,避免让你看到复杂的思考过程而感到困惑。简单来说,就是模型在给出答案之前先自己“思考”,但只跟你分享最终结论。
这就像我们在检查作业时,检查是否漏做了某个题目。这个过程帮助我们确保模型在分析问题或给出答案时,考虑到了所有重要的信息,没有忽略掉某些关键点。
举个例子,如果源文档很大,模型通常会过早停止且无法列出所有相关信息。在这种情况下,通过使用后续的 prompt 可以让模型查找之前错过的任何相关信息,通常可以获得更好的性能。
模型不是万能的,就比如它数学很垃圾,所以需要些外部工具来帮忙处理。
如果模型作为其输入的一部分提供,则可以利用外部信息源。这可以帮助模型生成更明智和最新的响应。例如,如果用户询问有关特定电影的问题,则将有关电影的高质量信息(例如演员、导演等)添加到模型的输入中可能很有用。嵌入可用于实现高效的知识检索,以便在运行时动态地将相关信息添加到模型输入中。
文本嵌入指的是通过将文本信息转换成数学上的向量形式,也就是嵌入,来进行信息的检索和匹配。这个过程首先涉及到将需要的知识信息(比如文章、报道等)分割成小块,并将这些文本块转换成向量,这样每个文本块就有了一个数学上的表示。
当有一个查询请求时,同样将这个查询转换成一个向量。然后,通过比较这个查询向量和存储的文本块向量之间的距离或相似度,来找出与查询最相关的那些文本块。
这种方法非常高效,因为向量之间的比较计算速度快,而且能够在大规模的数据中快速定位到最相关的信息。这样不仅提高了检索的速度,也提高了信息的相关性和准确性。
都知道模型的计算能力垃圾,所以 OpenAI 建议,如果遇到需要计算的东西,可以让模型写一段计算的 Python 代码,让它来执行。
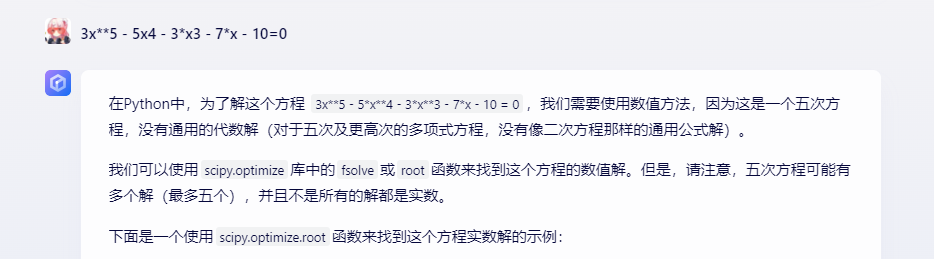
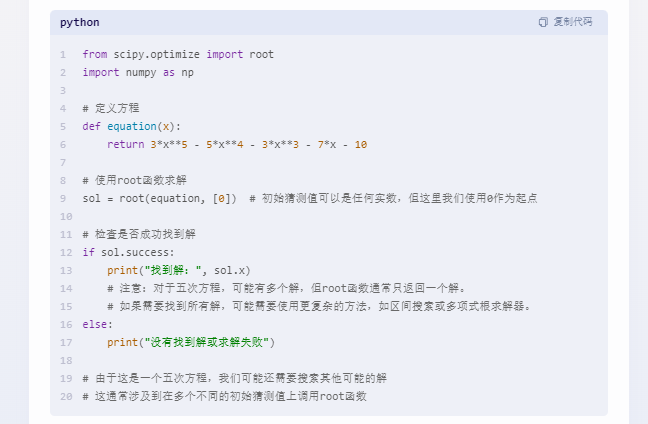
比如:您可以通过将 Python 代码括在三个反引号中来编写和执行 Python 代码,例如 '''code goes here'''。使用它来执行计算。
求下列多项式的所有实值根:3x**5 - 5x4 - 3*x3 - 7*x - 10。
既然都用Python了,也可以把自己的API文档复制给它,然后向模型提供演示如何使用 API 的文档和/或代码示例,指导模型如何使用 API。
Chat Completions API 允许在请求中传递函数的描述。这样,模型就可以生成符合这些描述的函数参数。这些参数以 JSON 格式由 API 返回,并可以用于执行函数调用。函数调用的结果可以再次输入到模型中,形成一个闭环。这是利用 OpenAI 模型来执行外部函数调用的推荐方法。
对于普通用户几乎没用。
主要是帮助开发者判断更改Prompt(例如新指令或新设计)是否使系统变得更好或更差。
文章来源:https://zhuanlan.zhihu.com/p/681722891